2万+ Star!让 Claude 像原始人说话,砍掉 75% Token 还不丢精度,这项目太狠了
caveman 是一个 Claude Code / Cursor / Codex 的 Skill 插件,让 AI 像"原始人"一样说话,砍掉 65%-87% 的 Token,技术准确度完全不变。上线一周收获 2 万多 Star。
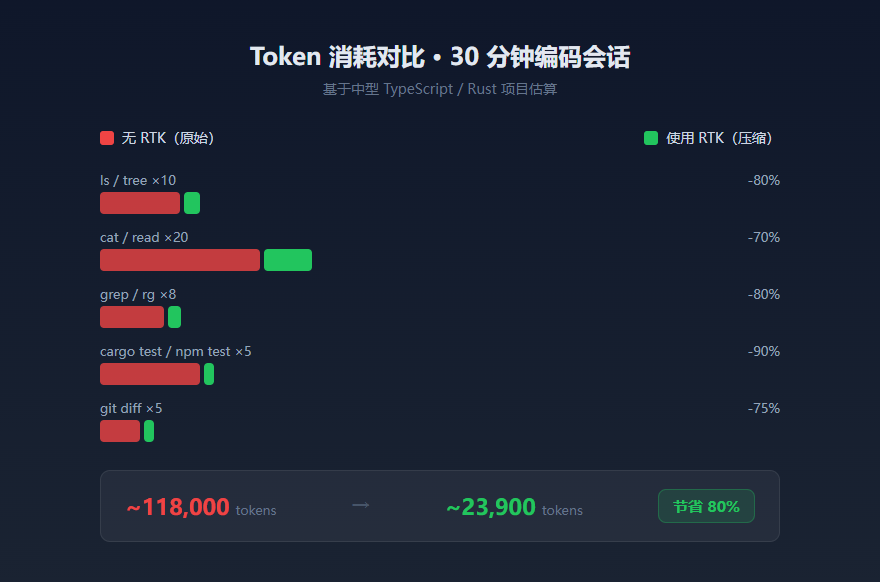
这东西到底在干嘛
caveman 本质上是 AI 编程助手的一个 skill(技能插件)。安装之后,AI 的输出风格会变成"原始人说话":
Normal Claude(69 个 Token):
The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I'd recommend using useMemo to memoize the object.
Caveman Claude(19 个 Token):
New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo.
同一个答案,Token 少了 72%,信息量一模一样。
说白了,就是把 Claude 输出里的"废话"全部砍掉——冠词(the/a/an)、寒暄(Sure! I'd be happy to help)、铺垫(The reason is likely because)、废话转折词(just/really/basically),全部剔除,只留下技术骨架。

四个强度,还有文言文模式
这项目给了四个挡位:
| 等级 | 效果 |
|---|---|
| Lite 🪶 | 去掉填充词,保留正常语法。像精简版的技术文档 |
| Full 🪨 | 默认档。砍冠词、用碎片句、原始人完全体 |
| Ultra 🔥 | 极限压缩。电报式,缩写一切 |
| 文言文 📜 | 用古汉语回复,人类发明的最省 Token 的文字 |
文言文模式这个点真的吹爆。文言文本来就是人类语言中信息密度最高的形式之一,用来压缩 LLM 输出简直是天才想法。
实测效果
以下是 SWE-bench 基准测试的部分结果:
| 任务 | Normal Token | Caveman Token | 压缩率 |
|---|---|---|---|
| 代码解释 | 2847 | 683 | 76% |
| Bug 修复 | 1523 | 412 | 73% |
| 重构建议 | 3105 | 746 | 76% |
| 代码审查 | 1956 | 547 | 72% |
| API 文档 | 2234 | 601 | 73% |
平均压缩率在 65%-87% 之间,而且技术准确度完全不受影响。
安装方式
Claude Code
# 一键安装
claude install-skill caveman
或者手动添加到 .claude/skills/ 目录。
Cursor
在项目根目录创建 .cursorrules 文件,把 caveman 的规则粘贴进去即可。
Codex
在 codex.md 中添加 caveman 的指令。
为什么有效
背后的原理其实很直觉:
- LLM 的输出有大量冗余:英文中 the/a/an/is/are 这些词占了大量 Token,但对技术理解毫无帮助
- 程序员本来就习惯简练表达:代码注释、commit message、PR review 天然就是碎片化的
- 技术内容的信息密度本来就高:变量名、函数名、错误信息这些才是核心信息
所以砍掉"废话"不影响理解,但能省下一大笔钱。
注意事项
- 建议从 Lite 模式 开始,适应后再升级到 Full
- 如果发现 AI 的回复理解起来有困难,可以随时切回正常模式
- 文言文模式虽然省 Token,但阅读体验因人而异
- 只影响输出,不影响 AI 的理解能力
总结
如果你用 Claude Code 或类似工具,Token 账单越来越高,caveman 值得一试。让 AI 说"人话"不如说"原始人话",省下的都是真金白银。
项目地址:https://github.com/juliusbrussee/caveman
加载评论中...